- Learn to "scrape" text/numbers from a website and use them in Python
- BeautifulSoup is the framework used
First, let me explain what web scraping is. Every website out there is fed to your browser by a stringently standardized html markup language. Scrapers take advantage of this by providing an easy framework for processing html elements such as tags, divs, and lists. A scraper essentially turns a website into a series of addressed strings, arrays, and integers.
Scope of Code
Anyone that knows me knows I play fantasy baseball religiously. One league that I’m a member of has a barebones interface and doesn’t calculate player statistics for me in a way that I’d like. They do, however, provide good raw numbers that could be analyzed and used to help set my daily lineups. Specifically, I’d like to see how a player has been “streaking”, or their performance over the past several games. Sure sure, past performance does not necessarily predict future performance, but this isn’t a sabermetrics conversation; it’s about learning python!
Let me state again what I need this program to do. I need it to look at a page that contains all of my team’s players, skim off the links to those individual players’ pages, go to each individual’s page, skim off their stats, do some math on those stats, and show me some analyzed numbers. This web scraping application may seem esoteric, but the concept could very easily be applied to things like stock market analysis, ebay listings, etc.
First thing’s first, BeautifulSoup needs to be available to your python installation. Use pip, easy_install, or your favorite method to get the package. If you don’t have access to a package manager, getting BeautifulSoup is more involved. Read about that situation here.
Start Using BeautifulSoup
Let’s start by introducing BeautifulSoup’s initialization syntax by loading a random webpage.
from bs4 import BeautifulSoup
from urllib import urlopen
optionsUrl = 'http://ottoneu.fangraphs.com/90/setlineups'
optionsPage = urlopen(optionsUrl)
soup = BeautifulSoup(optionsPage)
You can double check your code by adding a print(soup) line to code and running it. The terminal should output the entirety of the page’s html.
Web Scraping Actual HTML
The next step involves playing with your browser. Being familiar with the structure of html is handy in this case, but what we need to do is identify the tag/container/element where the information we’re looking for is located. I’m using Google Chrome to accomplish this, but Firefox with the Firebug plugin installed can also be used. Go to the website we’re looking at, select a random portion of the table that includes the players on the roster, right click, and select Inspect Element.
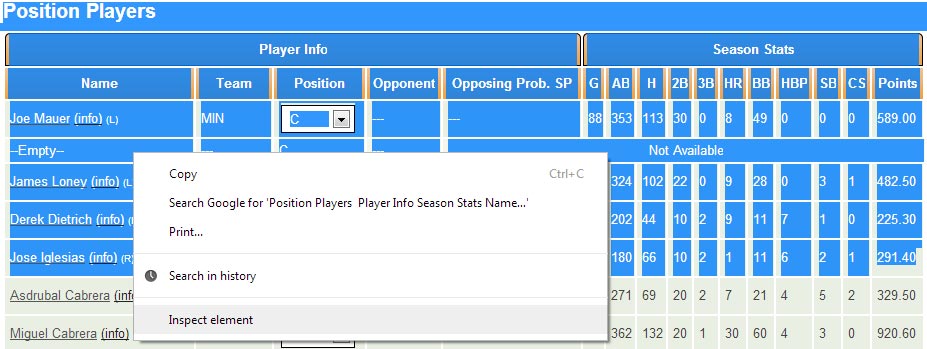
Chrome’s inspect element is really cool. As your mouse scrolls through the elements on the bottom of the screen, the different elements of the page will highlight for you. This is how to narrow down which part of the html contains the code we’re interested in.
In this case, each row (that’s a tr [table row]) is given a class, either ‘starter’ or ‘even’. If a player’s class includes ‘starter’, they’re in the fantasy team’s starting lineup. In any case, those same rows contain the links to the player pages we’re looking for.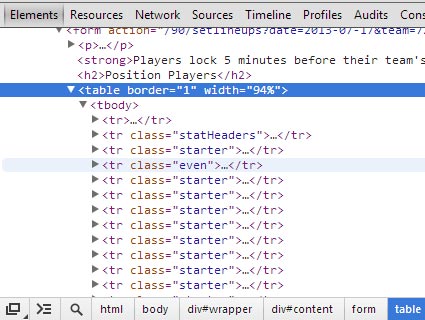
Using BeautifulSoup’s .findAll Method
Armed with this knowledge, we can go back to our Python code and use BeautifulSoup to pare the html code down into just the row elements we’re looking at. There’s a exhaustive resource available for BeautifulSoup’s web scraping capabilities, but we only need some of the most simple methods here.
for row in soup.findAll('tr',{ 'class' : ['starter' , 'even']}):
print(row)
What we’re doing is using a for loop to cycle through each instance the .findAll method comes up with. We’re feeding the .findall method the argument that we’re looking for ‘tr’ elements, and another argument that requires the tr element have a class of either ‘starter’ or ‘even’. Notice that second argument is given as a dictionary since there were two requirements. This will spit out more html for us. Upon further inspection, however, we can see that each row contains the element we’re looking for!
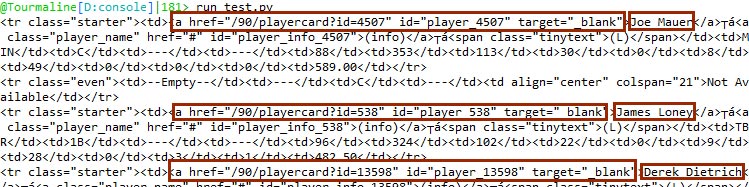
for row in soup.findAll('tr',{ 'class' : ['starter' , 'even']}):
col = row.findAll('a',{ 'target' : '_blank'})
print(col)
The results we’re getting now are almost what we’re wanting. Each player’s page link is being spit out by our script, but they each look to be in a list. Not every row necessarily has a link in it. The linkless rows correspond to unfilled roster positions, so more code is needed to eliminate these empty sets.
for row in soup.findAll('tr',{ 'class' : ['starter' , 'even']}):
col = row.findAll('a',{ 'target' : '_blank'})
if col: #this removes the empty list components
link = col[0]['href'] #get the link's href
player = col[0].text #record the player
- Here we’re embedding an if statement within the for loop to check to make sure that row that’s being output actually has something in it.
- Since each link is stored in a list in this case, we need to first access the first element of the list ([0]) before extracting its link
- We might as well get the player’s name while we’re at it
Go ahead and test the code by printing out the player and the link. You’ll notice that each of the links are relative (as opposed to absolute), so they need to be concatenated with the website’s root address. This is accomplished by storing a variable outside the for loop and combining it with the relative link when the variable is stored. Obtaining the full link is important, because the next step is to feed it to a function that can extract information from each page.
URL_BASE = "http://ottoneu.fangraphs.com"
link = URL_BASE + col[0]['href'] #get the link's href
The method to extract information from the individual players’ pages is similar to the techniques used above. There’s no need to go through that again. However, I’ve included the finished code here below for reference.
Finished Code
#Created by Andrew Cross
#7.17.2013
#http://www.agcross.com
#-----------------------------------------------
#This code is designed to scrape fantasy points
#from a fantasy baseball site and analyze them
#before displaying the results to the user
#-----------------------------------------------
from bs4 import BeautifulSoup
from urllib import urlopen
from time import sleep # be nice
def get_players_stats(player_url):
playerPage = BeautifulSoup(urlopen(player_url))
#Find the <h2> tag that shows where the Last 10 MLB Games stats are at
foundtext = playerPage.find('h2',text='Last 10 MLB Games')
table = foundtext.findNext('table') # Find the first <table> tag that follows it
points = 0
count = 0
for row in table.findAll('tr',{ 'class' : ['even' , 'odd']}):
col = row.find_all('td')
points = points + float(col[len(col)-1].text)
if count == 2:
last3_average = round(points/3,2)
count = count + 1
return str(last3_average) + ' ' + str(points/count)
optionsUrl = 'http://ottoneu.fangraphs.com/90/setlineups?team=726'
optionsPage = urlopen(optionsUrl)
URL_BASE = "http://ottoneu.fangraphs.com"
soup = BeautifulSoup(optionsPage)
#Start the loop that looks for td data
for row in soup.findAll('tr',{ 'class' : ['starter' , 'even']}):
col = row.findAll('a',{ 'target' : '_blank'})
if col: #this removes the empty list components
link = URL_BASE + col[0]['href'] #get the link's href
player = col[0].text #record the player
sleep(1) # be nice
print(player + ' ' + get_players_stats(link))
Other good sources of reference for web scraping:
http://shanebeirnes.wordpress.com/2012/07/28/web-scrapping-with-beautiful-soup-in-python/
http://www.gregreda.com/2013/03/03/web-scraping-101-with-python/